The Data Side of Event Driven Architecture โดย Mark Richards

เป็นอีกหนึ่ง Talk ที่ดี คุ้มค่าแก้การนั่งฟังครับ
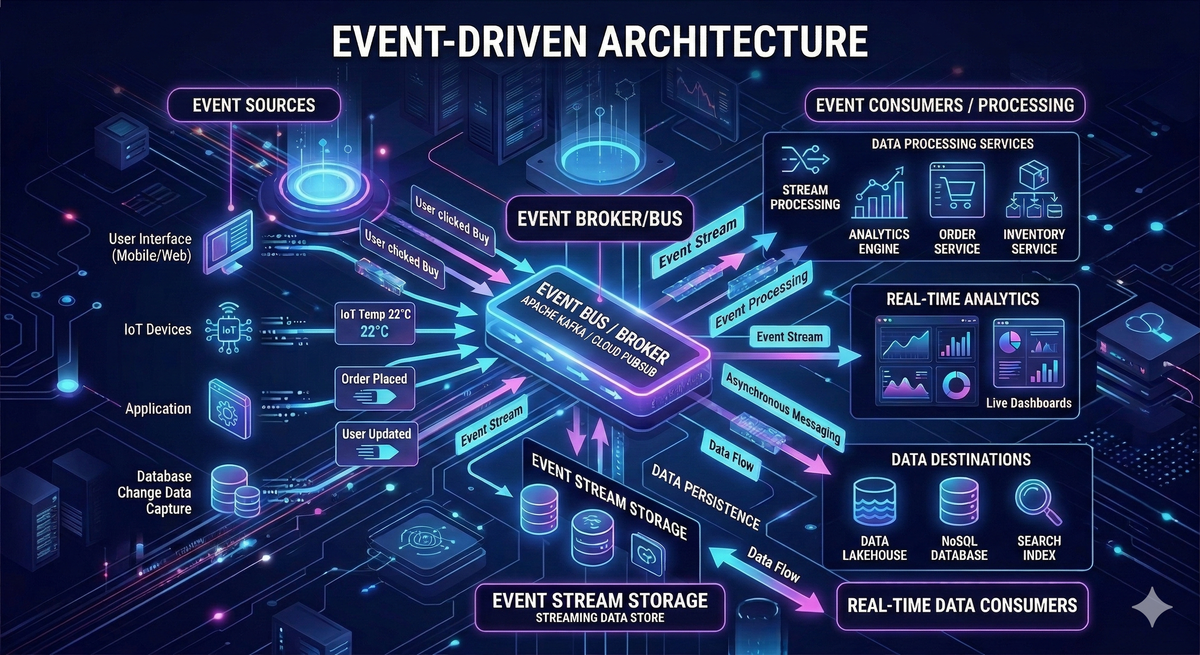
เค้าเล่าได้เพลินดีว่าเวลาเราทำ Event-Driven Architecture (EDA) มันหน้าตาประมาณไหน แล้วการใช้ Pattern อย่าง Event Contract Patterns มีแนวคิดอย่างไร เราควรเลือกแบบไหน ซึ่งแน่นอนว่าไม่ว่าเลือกทางไหนก็จะต้องเจอ
Trade-off
เช่น เดียวกับการเลือก Database Topologies ว่าจะมีเครื่องเดียว มีแยกตาม Domain หรือแยกไปทุก Services เลย แต่ละแบบก็มี Trade-off เช่นเดียวกัน ต้องดูที่ Use Cases & Scenarios (Business) ว่าเราควรเลือกแบบไหนเพื่อแก้ปัญหา
ทีนี้ก็สนุกตรงที่ว่าเวลาทำ EDA ไปเรื่อย ๆ แล้วถ้าเราไม่ได้คอยระวังเรื่องการเรียกข้อมูลจากแต่ละ Services ที่ไม่ได้ผ่าน Event เช่น เรียก API ของ Service นั้นตรง ๆ เลย ซึ่งก็จะเกิด Synchronous Calls ขึ้น แล้วถ้ามีเยอะ ๆ เข้า สุดท้ายแล้วระบบเราจาก EDA ก็จะย้ายกลับไปเป็น Monolith ซะงั้น แถมวอดวายกว่าเดิม เพราะแยก Services ออกจากกันไปแล้ว..
เค้าก็เลยบอกว่าวิธีแก้ปัญหาแบบนี้ แทนที่จะเรียก API ของ Service ตรง ๆ ให้เกิด Synchronous Call แล้ว เรายังสามารถทำ EDA ได้อยู่คือให้ ทำ Data Replication หรือ In-Memory Replicated Caching ซึ่งบอกได้เลยว่าเวลาเอาไปทำจริงมันไม่ได้มีแค่เรื่อง Replicate ข้อมูลอย่างเดียว มันยังมีเรื่อง Operations ที่จะตามด้วยเช่นกันที่เราต้องคำนึงถึงว่าจะทำอย่างไรให้ทั้งระบบและข้อมูลมันมีความ (Eventually) Consistent ไปต่อได้อย่างยั่งยืน
ซึ่ง.. วิธีแก้ปัญหาที่ว่ามาด้านเราก็จะเห็นว่ามันมี Trade-off อีก! 😂 จะทำอะไรก็มี Trade-off ไปหมดเลย ซึ่งก็นั่นแหละครับ ชีวิตจริงก็เป็นแบบนั้น
แล้วเอาจริง ๆ ใน Talk นี้เราจะได้ยินแต่คำด้านบนนี้บ่อยครั้งมาก เราหนีไม่พ้นคำ ๆ นี้แน่ ๆ ตราบใดที่เรายังทำงานในสายงานด้านนี้กันอยู่ ดังนั้นเวลาเราจะตัดสินใจอะไรก็ทำให้แน่ใจว่าเราได้เอา Business มาประกบแล้ว เพื่อให้มั่นใจได้ว่าเราได้แก้ปัญหาทาง Business แล้วจริง ๆ สุดท้ายพอเลือกวิธีแก้ปัญหาแล้วก็อย่าลืมเขียน Architectural Decision Records ไว้ด้วยนะ 😎
สรุปว่าคำว่า Data Side ใน Talk นี้ของเค้าก็หมายถึงเรื่องแบบนี้แหละ เราต้องตระหนักไว้เสมอด้วยว่า EDA ไม่ได้เป็น Silver Bullet มันจะมีเรื่องที่ Challenges อีกเยอะเวลาที่เราหยิบมาทำจริง
โดยเฉพาะเรื่องข้อมูล



