Parse, don’t validate

ผมได้รู้จัก Principle นี้ตอนศึกษาเรื่อง Type System และเร็วๆ นี้เพิ่งเห็นน้องในทีมนำ Library ที่ใช้แนวคิดนี้มาใช้ แต่พอเราไม่เข้าใจหลักการเบื้องหลัง (Core Principle) การนำไปใช้งานเลยติดขัดและเกิดปัญหาตามมา เลยคิดว่าน่าจะหยิบเรื่องนี้มาเล่าให้ฟังกันสักหน่อยครับ
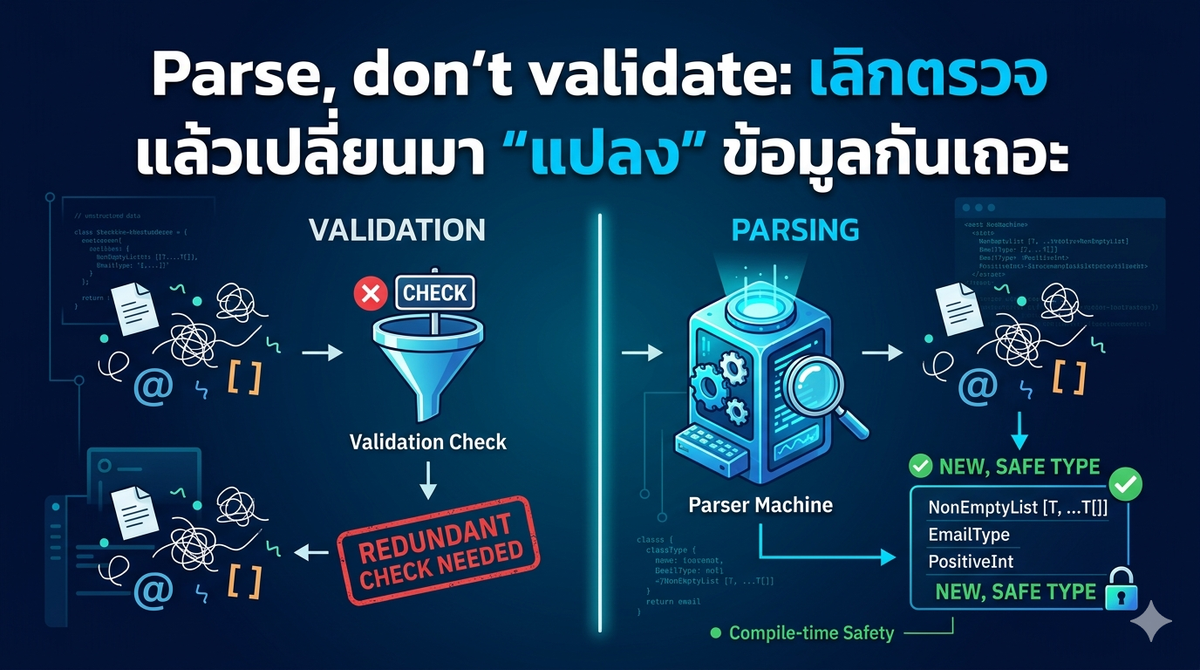
ทำไมการ "Validate" (ตรวจสอบ) ถึงไม่เพียงพอ?
ปกติเวลาเราพูดถึงการเช็คข้อมูล (Validation) เรามักจะนึกถึงฟังก์ชันที่รับ Data เข้ามา เช็คว่าถูกต้องตามเงื่อนไขไหม ถ้าไม่ถูกก็โยน Error แต่ถ้าถูกก็ปล่อยผ่านไป (คืนค่าเดิม หรือคืนค่า Boolean กลับไป)
ลองนึกภาพโค้ดที่เราเห็นกันจนชินตา:
"เรามักจะเช็ค Input ก่อนใช้งานเสมอ เช่น เช็คว่า List ไม่ว่างนะ, เช็คว่า String เป็น Email นะ... แต่เคยสงสัยไหมว่า พอส่งตัวแปรนี้ต่อไปยังฟังก์ชันถัดไป ทำไมเรายังต้องมานั่งเขียน if เช็คเรื่องเดิมซ้ำอีก? หรือถ้าลืมเช็ค โปรแกรมก็พังคามือเป็น Runtime Error ทันที"ปัญหาคือ: การ Validate แบบนี้ไม่ได้ทิ้ง "หลักฐาน" อะไรไว้ในระบบ Type เลยว่าข้อมูลนี้ปลอดภัยแล้ว ความรู้ (Knowledge) ที่เราได้มาจากการเช็คหายวับไปทันทีที่จบฟังก์ชันนั้น นี่คือสัญญาณว่าเรากำลังใช้ Type System ได้ไม่คุ้มค่าครับ
พลังของการ "Parse": เปลี่ยนจากด่านตรวจ เป็นโรงงานแปรรูป
การเปลี่ยนจาก Validate มาเป็น Parse คือการเปลี่ยนวิธีคิด แทนที่จะแค่ "ตรวจสอบ" เฉยๆ เราจะ "แปลง" ข้อมูลจากโครงสร้างที่ หลวมและไม่แน่นอน (Less-structured) ให้กลายเป็นโครงสร้างที่ ชัดเจนและเข้มงวด (More-structured)
ลองดูตัวอย่างการใช้ NonEmptyList แทน List ทั่วไป:
- สร้างความมั่นใจผ่านโครงสร้าง: แทนที่จะรับ List ปกติ
[a]ที่อาจจะว่างก็ได้ เราเปลี่ยนมารับNonEmptyList aซึ่งโครงสร้างของมันบังคับว่าต้องมีสมาชิกอย่างน้อยหนึ่งตัวเสมอ - ลดภาระของฟังก์ชัน: เมื่อ Type บังคับมาแล้ว ฟังก์ชัน
head(ดึงตัวแรก) ก็สามารถคืนค่าได้ทันทีโดยไม่ต้องลุ้นว่าเป็นnullหรือเปล่า - พิสูจน์ครั้งเดียวจบ: เราย้ายการตรวจสอบไปไว้ที่ "ขอบหน้าต่าง" ของโปรแกรม (Boundary) เพียงครั้งเดียวเพื่อแปลง List ปกติให้เป็น
NonEmptyList
หลังจากจุดนั้นเป็นต้นไป ระบบ Type จะเป็นคนช่วย "พิสูจน์" (Proof) ให้เราเอง ว่าข้อมูลนี้ถูกต้องแน่นอนตลอดทั้งโปรแกรม โดยที่เราไม่ต้องเขียน if เช็คซ้ำอีกเลย
Validation vs. Parsing: มุมมองของ "ข้อมูล" และ "ความรู้"
- Validation: คือการเช็คว่าข้อมูล "เลวร้าย" ไหม ถ้าไม่ ก็ปล่อยผ่านไป (คืนค่าเดิม)
- จุดอ่อน: ความรู้ที่ว่า "ข้อมูลนี้ถูกต้องแล้ว" จะหายไปทันทีที่จบฟังก์ชันนั้น
- Parsing: คือการนำข้อมูลดิบ (Less structured) มาแปลงเป็นข้อมูลที่มีโครงสร้างชัดเจนขึ้น (More structured)
- จุดแข็ง: ข้อมูลใหม่ที่ได้มาคือ "หลักฐาน" ในเชิง Type ว่าข้อมูลนี้ถูกต้องแน่นอน 100%
เริ่มต้นเปลี่ยนวิธีเขียนโค้ดอย่างไรดี?
- เน้นที่ Data Types: เลือกใช้โครงสร้างข้อมูลที่ทำให้ "สถานะที่ผิดกฎหมายไม่สามารถเกิดขึ้นได้" (Make illegal states unrepresentable) เช่น ใช้
Mapแทน List ของ Key-Value เพื่อป้องกัน Key ซ้ำ - ผลักภาระการพิสูจน์ขึ้นไปให้สูงที่สุด: พยายาม Parse ข้อมูลให้เป็นรูปแบบที่แม่นยำที่สุดตั้งแต่จุดที่รับข้อมูลเข้ามา (เช่น จาก API หรือ User Input) ก่อนจะส่งต่อเข้าไปในโปรแกรม
- เขียนฟังก์ชันตามข้อมูลที่ "อยากให้เป็น": อย่าเขียนโค้ดตามรูปแบบข้อมูลที่ได้รับมา แต่ให้เขียนตามรูปแบบที่คุณต้องการ แล้วค่อยหาวิธีแปลงข้อมูล (Bridge the gap) มาสู่จุดนั้น
- ให้ระวังฟังก์ชันที่คืนค่าว่าง (Unit): ฟังก์ชันที่รับค่าไปตรวจสอบแล้วไม่คืนอะไรกลับมา นอกจาก Error เมื่อผิดพลาด มักจะเป็นจุดที่ข้อมูล "ความรู้" รั่วไหล เพราะมันไม่ได้ส่งต่อ Type ที่ดีกว่าเดิมออกมา
ตัวอย่างเปรียบเทียบใน TypeScript
แบบเดิม (Validation): เสี่ยงและซ้ำซ้อน
function processList(items: string[]) {
if (items.length === 0) throw new Error("List is empty");
// แม้จะเช็คแล้ว แต่ 'items' ก็ยังเป็น string[] ทั่วไป
// ฟังก์ชันอื่นที่รับ items ไป ก็ต้องมาเช็คซ้ำอีกอยู่ดี
const head = items[0];
}แบบใหม่ (Parsing): ปลอดภัยและชัดเจน
// สร้าง Type ใหม่ที่การันตีว่า "ต้องมีข้อมูล"
type NonEmptyList<T> = [T, ...T[]];
function parseNonEmpty<T>(items: T[]): NonEmptyList<T> | null {
return items.length > 0 ? (items as NonEmptyList<T>) : null;
}
function processList(items: NonEmptyList<string>) {
// ไม่ต้องเช็ค if (items.length === 0) อีกต่อไป!
// เพราะ Type บังคับมาแล้วว่าส่ง List ว่างมาไม่ได้
const head = items[0];
}ปล. อย่าพึ่งด่าผมนะ ผมยังไม่เก่ง TypeScript ขนาดที่จะทำให้โค้ดใน TypeScript มันฉลาดพอจะเป็น Proof ในระดับ Type บน Compile Time ได้ ผมเลือกมาเพราะคิดว่าคนส่วนใหญ่น่าจะพออ่านเข้าใจ แต่ผมเชื่อว่ามันทำได้นะ
ประโยชน์ที่ได้
- Code สะอาดขึ้น: ลด
if-elseเช็ค Error ยิบย่อยใน Business Logic - เป็นเอกสารในตัว (Self-documenting): แค่อ่าน Signature ของฟังก์ชันก็รู้แล้วว่ามันต้องการข้อมูลแบบไหน
- ความปลอดภัยสูง: ลดความเสี่ยงเรื่อง Security เช่น Injection ต่างๆ เพราะข้อมูลถูก Parse ให้เป๊ะตั้งแต่ปากทางเข้า (Boundary)
- ลดการเกิด Shotgun Parsing: การทำสิ่งนี้จะทำให้โปรแกรมถูกแบ่งเป็น Parsing phase และ Execution Phase ซึ่งทำให้โค้ดสำหรับตรวจสอบข้อมูลจะไม่ถูกถูกกระจายไปทั่วทุกส่วนของโปรแกรมปนกับ Business Logic (ซึ่งเป็นสาเหตุหลักของ Bug ที่หาตัวยาก)
การเปลี่ยนจาก "ตรวจสอบ" มาเป็น "แปลงข้อมูล" อาจจะดูเหมือนต้องเขียนโค้ดเพิ่มขึ้นในตอนแรก แต่มันจะช่วยให้คุณและทีมทำงานง่ายขึ้นในระยะยาว เพราะเราให้ Compiler ช่วยทำงานแทนเรานั่นเองครับ :)



